




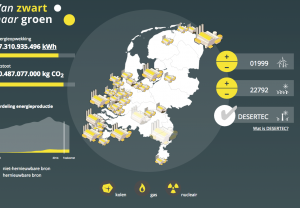
Data
Datablog: Hart en Ziel lijst.

Tussen 14 en 18 oktober was er op Radio 4 de Hart en ziel lijst te horen, een top 300 waarin mensen konden stemmen op de klassieke muziek die hun het meeste raakt (troost, ontspant, ontroert, inspireert, vrolijk maakt of met weemoed vervult) en de verhalen/herinneringen die daarbij horen.
Dataset stemuitslag met verhalen 2013.
De dataset bevat informatie over de 599 nummers waarop gestemd is en de persoonlijke verhalen die mensen daarbij geschreven hebben. De set bevat 1457 regels bestaande uit de volgende veld
en: id, artiest, nummer, aantal stemmen, aantal verhalen, verhaal. Bij het winnende nummer hebben 32 mensen een persoonlijk verhaal geschreven.
Een voorbeeld.
“Hart en Ziel,
Ik vraag me soms af waarom ik me zo door kunst, literatuur, natuur of muziek getroost voel. Zelfs als ik niet weet waarom ik getroost moet worden kan ik plotseling geraakt worden, door iets wat ik hoor zie of voel. Ik denk dat het iets te maken heeft met het geraakt zijn door de schoonheid die door een ander vormgegeven is waardoor je weet dat je niet alleen bent met dit gevoel in de diepste lagen van je zijn. Dat is troost. Schoonheid geeft troost,
In een periode waarin er weer eens hard gesproken en gepolariseerd werd over “anderen” en de Islam etc. deed ik `s morgens mijn autoradio aan. Ik viel direct in wat ik dacht Arabische muziek en voordat ik me raliseerde welke muziek het was biggelde de tranen over mijn wangen. De emotie ging voor het luisteren uit.
Toen ik iets langer luisterde hoorde ik dat het ging om Erbarme Dich van Sebastiaan Bach.
Het verlangen naar troost is universeel. (en dat is op zich een grote troost)
De uitvoering die ik hoorde was van Fadia El Hage”
Bijbehorende velden: Bach, Johann Sebastian, Matthäus Passion, 63 stemmen.
Welnu, wat kan je met deze data? Met name de tekstomschrijvingen zijn opvallend, en het is voor te stellen dat nummers geclassificeerd kunnen worden op basis van deze omschrijvingen. Wat het moeilijk maakt, is dat het veelal omschrijvingen zijn van emoties. Met tf-idf zou je uit bovengenoemde tekst het woord troost kunnen halen. Wat je daarvoor eerst moet doen is het artikel in woorden hakken, en stemming uitvoeren. Stemming zorgt er voor dat vervoegingen van werkwoorden omgezet worden naar een uniform woord. Hierdoor worden: troost, getroost, troostte allen omgezet naar het woord troost. TF-IDF telt dan de voorkomens van de woorden en zet deze af tegen hoe vaak een woord in de andere documenten voorkomt. Woorden als de, het, een , op , onder, kortom, die overal veel voorkomen vallen dan weg, en typerende woorden blijven dan over. Met LDA analyse kan je woorden die onderling vaak gebruikt worden identificeren: troost, verdriet, regen kunnen dan een cluster vormen.
tim
Laatste berichten van tim (toon alles)
- Datablog: Hart en Ziel lijst. - 5 november 2013